

[[415025]]
本文转载自微信公众号「飞天小牛肉」,作者飞天小牛肉。转载本文请联系飞天小牛肉公众号。
前文提到,对于 InnoDB 来说,随时都可以加锁(关于加锁的 SQL 语句这里就不说了,忘记的小伙伴可以翻一下上篇文章),但是并非随时都可以解锁。具体来说,InnoDB 采用的是两阶段锁定协议(two-phase locking protocol):即在事务执行过程中,随时都可以执行加锁操作,但是只有在事务执行 COMMIT 或者 ROLLBACK 的时候才会释放锁,并且所有的锁是在同一时刻被释放。
并且,行级锁只在存储引擎层实现,而对于 InnoDB 存储引擎来说,行级锁又分三种,或者说有三种行级锁算法:
Record Lock:记录锁 Gap Lock:间隙锁 Next-Key Lock:临键锁下面,我们来详细解释下这三种行锁算法。
Record Lock 记录锁顾名思义,记录锁就是为某行记录加锁,事实上,它封锁的是该行的索引记录。如果表在建立的时候没有设置任何一个索引,那么这时 InnoDB 存储引擎会使用 “隐式的主键” 来进行锁定。
所谓隐式的主键就是指:如果在建表的时候没有指定主键,InnoDB 存储引擎会将第一列非空的列作为主键;如果没有的话会自动生成一列为 6 字节的主键。
那么,既然 Record Lock 是基于索引的,那如果我们的 SQL 语句中的条件导致索引失效(比如使用 or) 或者说条件根本就不涉及索引或者主键,行级锁就将退化为表锁。
Record Lock 示例先来举个对索引字段进行查询的例子,有数据库如下,id 是主键索引:
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
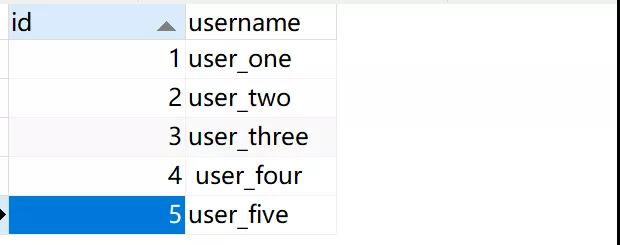
初始数据是这样的:
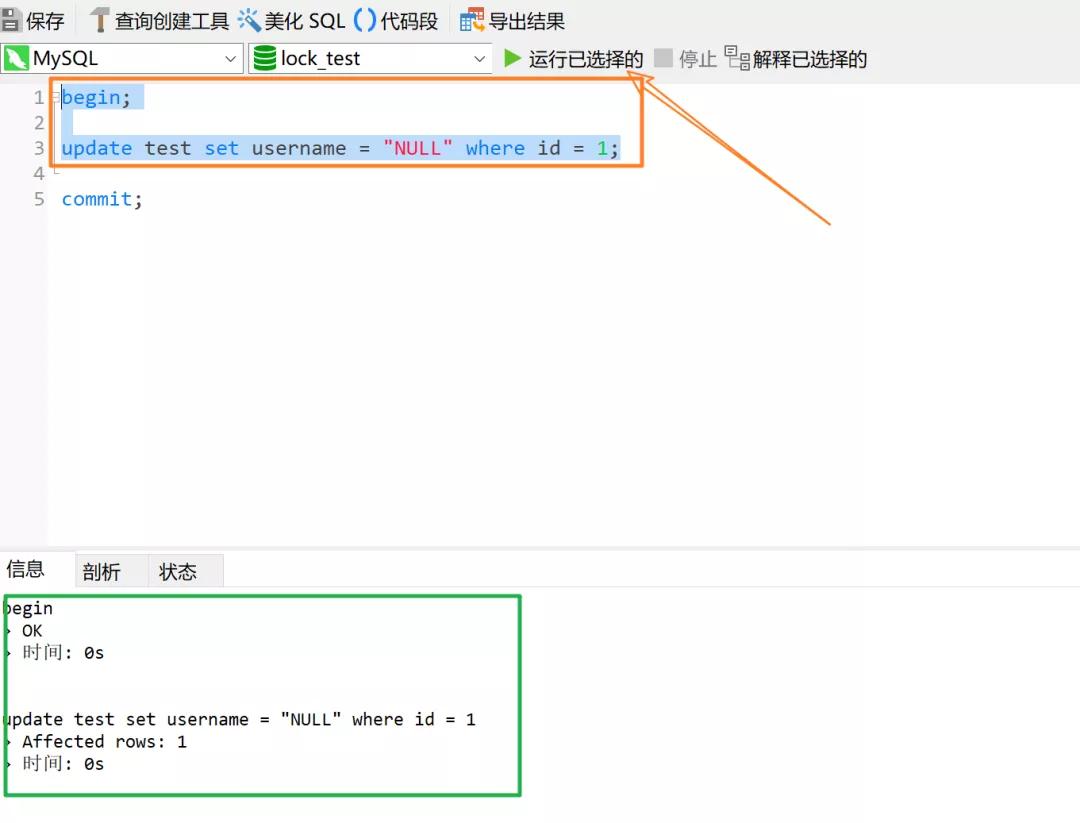
新建两个事务,先执行事务 T1 的前两行,也就是不要执行 commit:
 BOB半岛官方
BOB半岛官方
由于没有执行 commit,所以这个时候事务 T1 没有释放锁,并且锁住了 id = 1 的记录行,此时再来执行事务 2 申请 id = 2 的记录行:
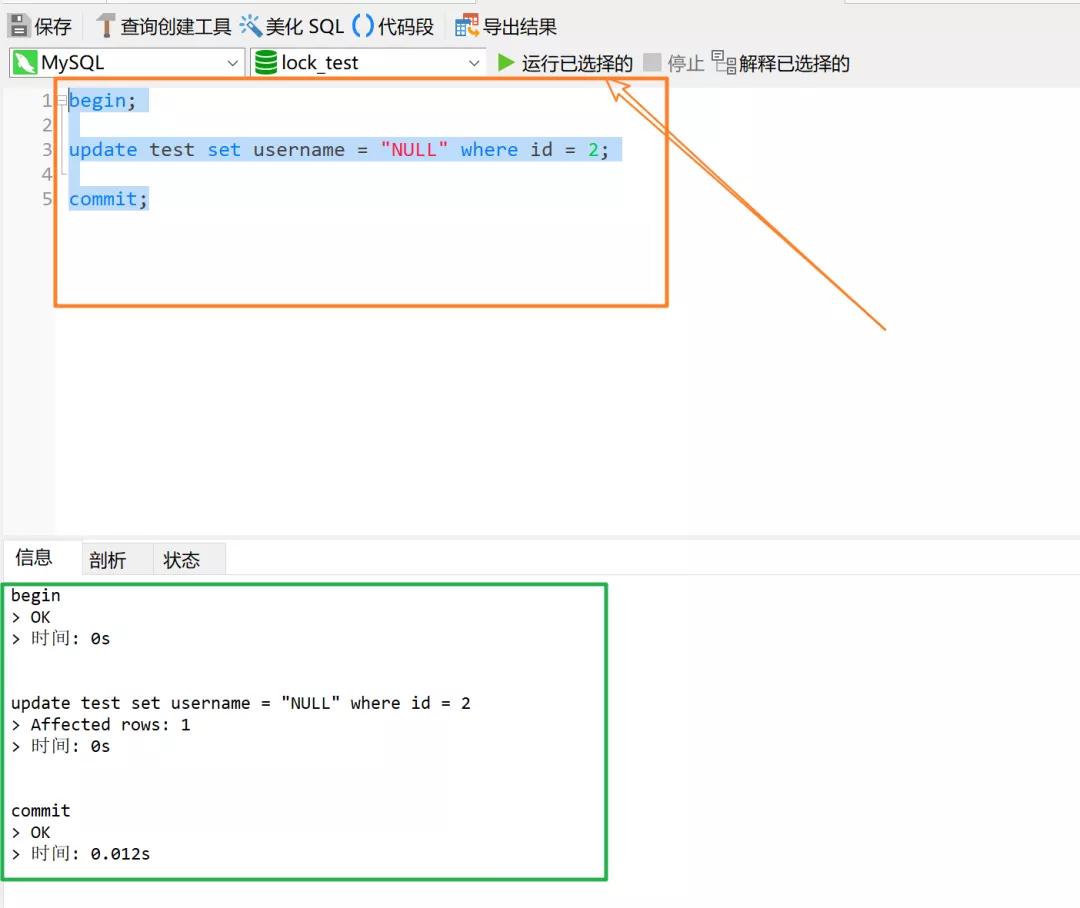
可以看见,由于锁住的是不同的记录行,所以两个记录锁并没有相互排斥,来看一下现在表中的数据,由于事务 1 还没有 commit,所以应该是只有 id = 2 的 username 被修改了:
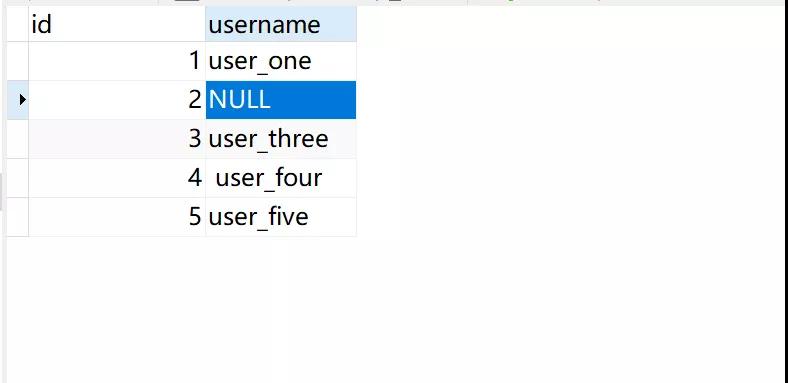
nice,果然。再执行下事务 1 的 commit,id = 1 的 username 也就被修改过来啦。
行锁退化为表锁示例再来看下没有使用索引的例子:
同样的,新建两个事务,先执行事务 T1 的前两行,也就是不要执行 commit。我们试图使用 select ... for update 给 username = "user_three" 的记录行加上记录锁,但是由于 username 并非主键也并非索引,所以实际上这里事务 T1 锁住的是整张表:
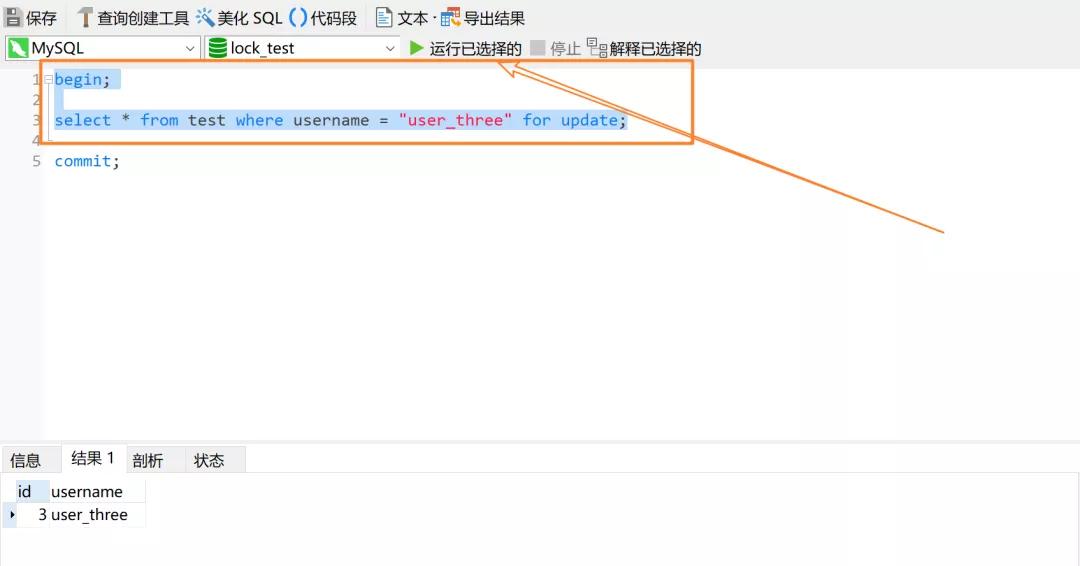
由于没有执行 commit,所以这个时候事务 T1 没有释放锁,并且锁住了整张表。此时再来执行事务 2 试图申请 id = 5 的记录锁,你会发现事务 T2 会卡住,最后超时关闭事务:
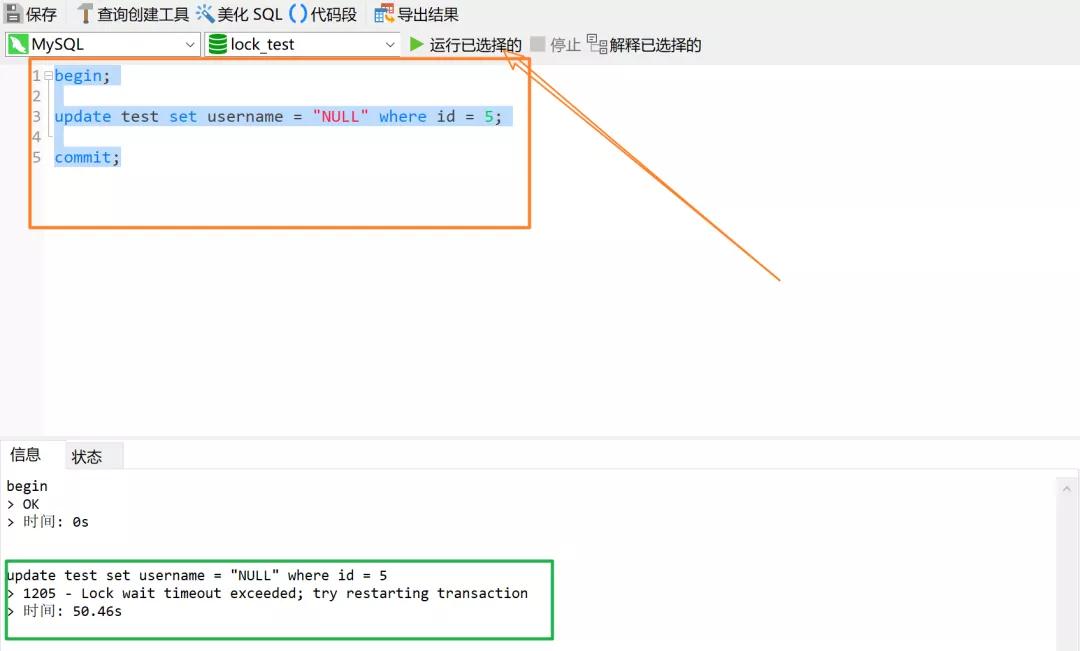
两条不同记录拥有相同的索引,会发生锁冲突吗?
这个问题的答案应该很简单吧,上面我们强调过,行锁锁住的是索引,而不是一条记录(只不过我们平常这么说锁住了哪条记录,比较好理解罢了)。所以如果两个事务分别操作的两条不同记录拥有相同的索引,某个事务会因为行锁被另一个事务占用而发生等待。
Gap Lock 间隙锁这里我先简单提一嘴,下文会详细解释:不同于 Record Lock 是基于唯一索引的,Gap Lock 和 Next-Key Lock 都是基于非唯一索引的。
并且,不同于 Record Lock 锁定的是某一个索引记录,Gap Lock 和 Next-Key Lock 锁定的都是一段范围内的索引记录:
select * from test where id between 1 and 10 for update;
对于上述 SQL 语句,所有在(1,10)区间内(左开右开)的记录行都会被 Gap Lock 锁住,所有 id 为 2、3、4、5、6、7、8、9 的数据行的插入会被阻塞,但是 1 和 10 两条被操作的索引记录并不会被锁住。
注意!这里指的是锁住所有的(1,10)区间内的 id,也就是说即使某个 id 目前并不在我们的表中比如 id = 6 ,如果你想插入一条 id = 6 的新纪录,那对不起,不行。
Next-Key Lock 临键锁Next-Key Lock 是结合了 Gap Lock 和 Record Lock 的一种锁定算法,其主要目的是为了解决幻读问题。
例如一个索引有 10,11,13 和 20 这四个值,分别对这个 4 个索引进行加锁操作,那么这四个操作分别对应的 Next-Key Lock 锁住的区间是:
(-∞, 10] (10, 11] (11, 13] (13, 20] (20, +∞]细心的同学应该已经注意到了,和 Gap Lock 的不同之处就在于,Next-Key Lock 锁定的区间是左开右闭的,也就是说它是包含当前被操作的索引记录的。
在 InnoDB 默认的隔离级别 REPEATABLE-READ 下,行锁默认使用的算法就是 Next-Key Lock。但是,如果操作的索引是唯一索引或主键,InnoDB 会对 Next-Key Lock 进行优化,将其降级为 Record Lock,即仅锁住索引本身,而不是范围。
由于主键也是一种唯一索引,所以我们可以这么说:Record Lock 是基于唯一索引的,而 Next-Key Lock 是基于非唯一索引的。
需要注意的,当操作的索引为非唯一索引时,InnoDB 会先用 Record Lock 锁住对应的唯一索引,再用 Next-Key Lock 和 Gap Lock 对这个非唯一索引进行处理,而不仅仅是锁住这个非唯一索引。具体地我们举个例子来看下。
Next-Key Lock 示例假设我们为上面 test 表中新增一个字段,并设置为非唯一索引:
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, `class` int(11) NOT NULL, PRIMARY KEY (`id`), KEY `index_class` (`class`) USING BTREE COMMENT '非唯一索引' ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
插入一些数据:
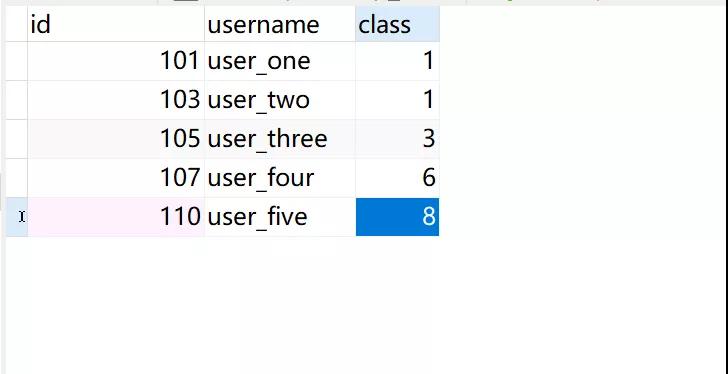
开启一个事务 1 执行如下的操作语句:
select * from test where class = 3 for update;
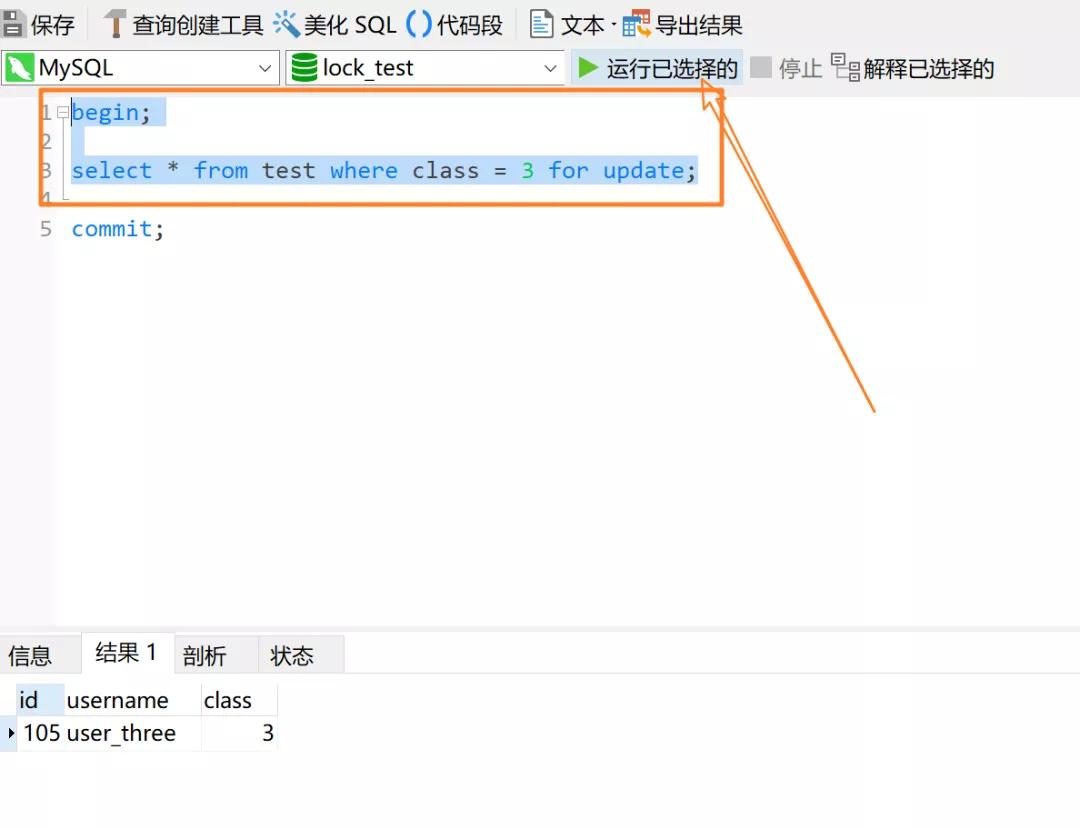
在这种情况下,InnoDB 事实上会加上三种行锁(select * ... from update 加的是行级写锁即 X 锁):

1)给主键索引 id = 105 加上 Record Lock
2)对于非唯一索引 class = 3,其加上的是 Next-Key Lock,锁定的范围是 (1,3]BOB半岛APP
3)另外,特别需要注意的是,InnoDB 存储引擎还会对非唯一索引 class 的下一个键值加上 Gap Lock(表中 class = 3 的下个键值是 6),所以还有一个 class 索引范围为 (3,6) 的间隙锁
总结下 2)和 3),对于这条 SQL 语句,InnoDB 存储引擎锁定地 class 索引范围是 (1, 6)
下面我们用实践来验证理论,再开启一个事务 2,执行下述的语句:
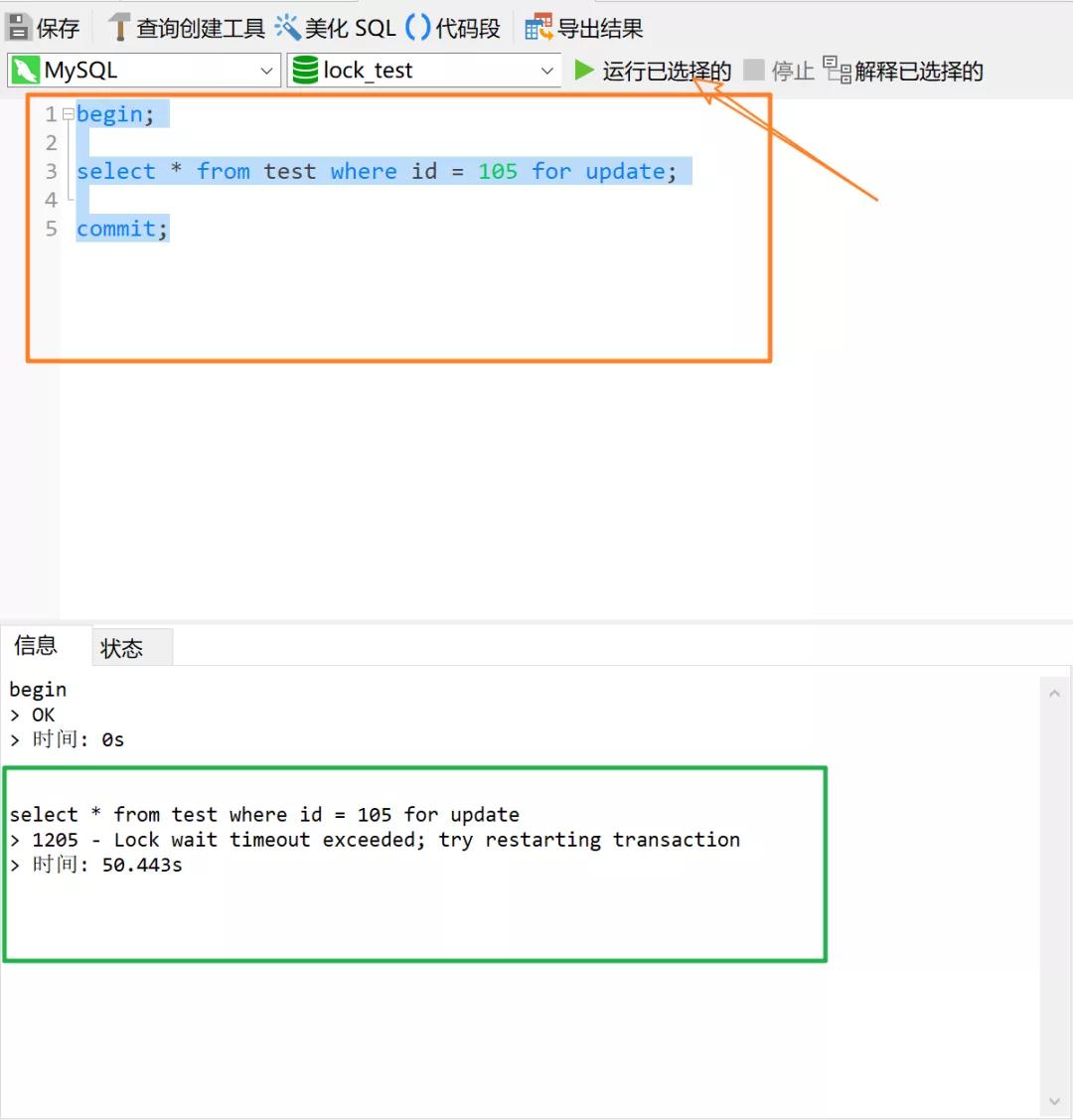
不出所料,由于在事务 1 中执行的 SQL 语句已经对主键索引中列 a=105 的记录加上了 X 锁,所以此处再去获取 这个记录的 X 锁会被阻塞住。
再用一个事务来执行下述 SQL 语句:


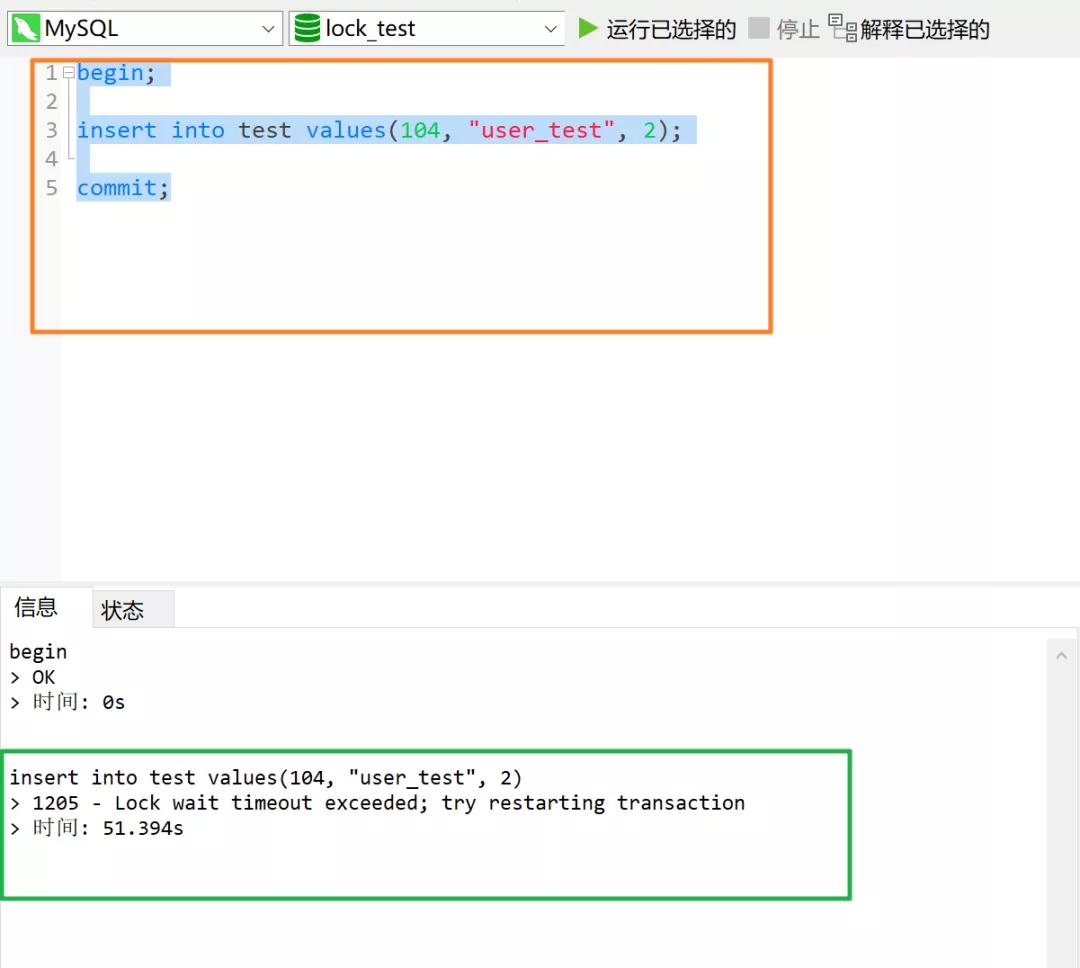
主键插入 104 没有任何问题,但是插入的 class 索引值 2 在被锁定的范围 (1,6) 中,因此执行同样会被阻塞住。
经过上面的分析,大家一定能够知道下面的 SQL 语句是可以正常执行的:
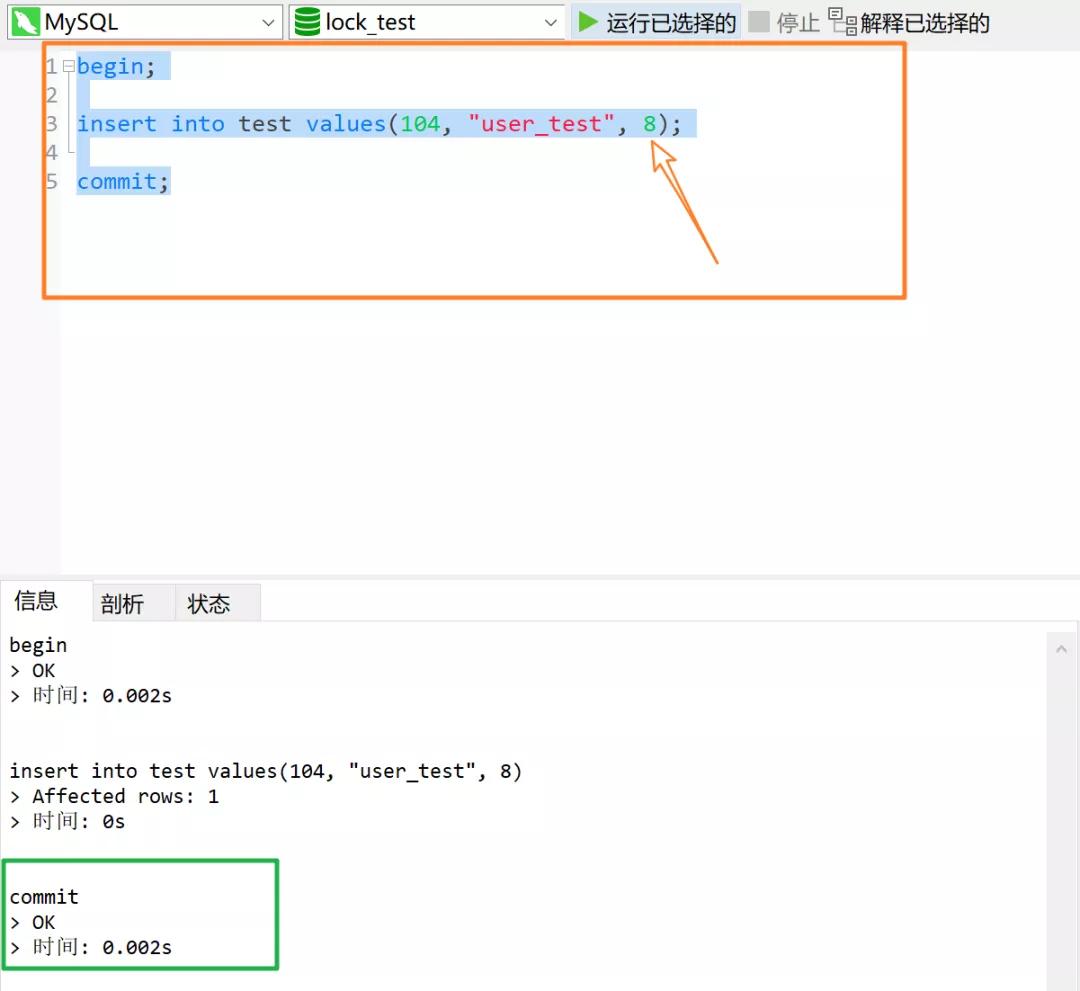
需要注意的是,Next-Key Lock 降级为 Record Lock 仅存在于操作所有的唯一索引列的情况BOB半岛平台。若唯一索引由多个列组成,而操作的仅是多个唯一索引列中的其中一个,那么 InnoDB 存储引擎依然使用 Next-Key Lock 进行锁定。